作者:虎仔球妈_459 | 来源:互联网 | 2023-10-11 06:47
篇首语:本文由编程笔记#小编为大家整理,主要介绍了分布式数据存储与管理[HDFS+HBase]相关的知识,希望对你有一定的参考价值。
一、系统架构
在分布式存储领域,相信大多数人对HDFS(Hadoop Distributed File System)并不陌生,它是GFS(Google File System)的开源实现版本,解决大规模非结构化数据存储的问题。然而,HBase则是基于HDFS之上的一个分布式的、面向列存的开源NoSQL数据库,解决大规模结构化和半结构化数据存储的问题。
a) HDFS架构
HDFS[1][2]采用Master/Slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成,如图1所示。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
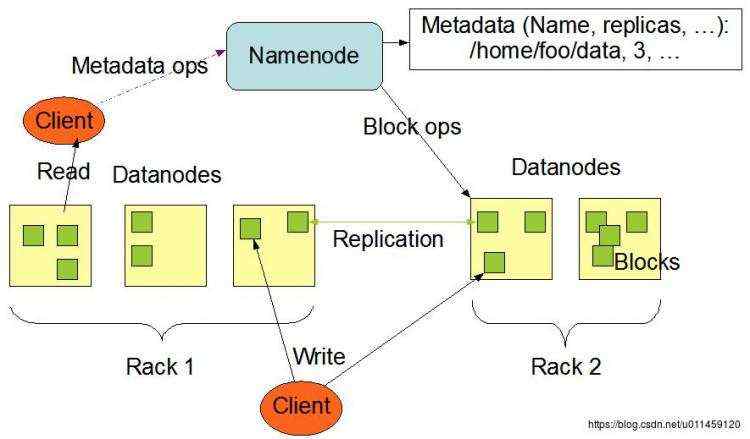
图1 HDFS系统架构
b) HBase架构
HBase[3][4][5]也同样采用Master/Slave架构。一个HBase集群是由一个HMaster和一定数目的RegionServer组成,如图2所示。HBase的一张表会被切分成若干块,每块叫做一个Region。每个Region中存储着从startKey到endKey中间的记录。这些Region会被分到集群的各个节点上去存储,每个节点叫做一个RegionServer,这些节点负责数据的读写,一个RegionServer可以处理大约1000个Regions。HMaster的功能是处理Region的协调工作,具体包括:管理RegionServer,实现其负载均衡;管理和分配Region,比如在Region Split时分配新的Region;在RegionServer退出时迁移其内的Region到其他RegionServer上;监控集群中所有RegionServer的状态(通过Heartbeat和监听ZooKeeper中的状态);处理Schema更新请求(创建、删除、修改Table的定义)。

图2 HBase系统架构
有一个的特殊的HBase目录表,.META表,保存了集群中Regions的位置。HBase读写流程,如图3所示。

图3 HBase读写流程
当客户端第一次读取(写入)HBase请求到达时:
- 第一步:客户端从HMaster中获取.META表; 第二步:客户端将查询.META表来获取要访问的row
- key对应的RegionServer,并将这些信息与.META表格一起缓存起来。
- 第三步:将从相应的RegionServer获取该行(写入该行到相应的RegionServer。
二、分析与对比
HDFS+HBase与单机中的数据库+文件系统类似,但又不完全一样。首先,HBase不实现复制机制,而是交给底下的HDFS系统,HDFS则会把一个块写入到多个数据节点中。因此,HBase更像维护表格与文件之间映射关系的一个计算引擎。如果用Aurora或PolarDB中的描述方式,HBase是控制面(控制引擎),HDFS则是数据面(存储引擎),只不过这两种层级分布在不同的系统之中而已。其次,HBase与传统的关系型数据库对外接口不同,仅支持API接口,不支持SQL语言,也不支持Join等操作,也放松了ACID属性,所以,它是一个NoSQL型数据库。
像HDFS+HBase这样分布式数据存储与管理系统,它们将控制和存储两大模块进行分层,分别在两个相对独立的分布式系统中实现。不难发现,这种实现方式既存在优点,也存在弊端。因为层次化的设计可以使整个系统的耦合度和复杂度降低,也可以使整个系统的每一个部分相对独立,也更具有通用性和一般性。然而,这样相对独立的设计也给整个系统带来许多不必要的开销,降低了系统的整体性能。在每一个独立的系统中,都有一整套Master/Slave架构,上一层系统充当下一层系统的Client端,这就使整个数据存储的路径变长了,例如,一次简单写操作要既经过HBase的Master也要经过HDFS的Master。随着越来越多的应用对低时延、高吞吐量特性的需求,这样的设计也就很难满足了。所以,整个系统就必须高度融合,尽可能减少不必要的网络和存储开销,使整个读/写路径变的更短,才使整系统的性能得以提升。换句话说,当前的HDFS+HBase软件栈太重了,我们必须将其减负才能实现低时延、高吞吐量的特性。
如果我们换个角度看问题,HDFS+HBase其本质也是一种shared disk的架构,整个HBase集群共享下层HDFS存储池。相信大多数人已经对shared disk VS shared nothing问题[7][8]不言而喻了,就不再赘述了。除了上述问题以外,HBase采用列存储的方式,很难应对OLTP型的负载,并且它的数据恢复也采用WAL的方式,导致其恢复时间较长,也存在不可靠的分裂问题[6]。
三、小结
像HDFS+HBase这样,由多个独立的分布式系统组成的数据存储与管理解决方案,各个系统更具一般性和通用性,但是很难满足用户对更低时延、更高吞吐量的追求。为实现更高性能,整个系统之间必须高度融合,更具定制化,尽可能缩短数据处理的路径,从而减少不必要的开销。
参考文献:
[1] http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html.
[2] https://www.cnblogs.com/laov/p/3434917.html.
[3] https://mapr.com/blog/in-depth-look-hbase-architecture.
[4] https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-bigdata-hbase/index.html.
[5] https://www.edureka.co/blog/overview-of-hbase-storage-architecture.
[6] https://www.toadworld.com/platforms/nosql/b/weblog/archive/2013/10/14/avoiding-hbase-reliability-problems.
[7] http://www.benstopford.com/2009/11/24/understanding-the-shared-nothing-architecture.
[8] Lee S. Shared-nothing vs. shared-disk cloud database architecture[J]. International Journal of Energy, Information and Communications, 2011, 2(4).










 京公网安备 11010802041100号
京公网安备 11010802041100号